

【最新版】流行りのOCRフリーソフト9選

概要
画像やPDFから文字を認識するには、OCRソフトが必要です。この記事は、使いやすく、流行りのOCRフリーソフトをすすめ、使い方を紹介します。

雑誌、書籍、契約書、新聞などを認識して、パソコンが読める電子ワードに変換し素早くパソコン入力したい場合は、OCRソフトを利用できます。手動入力せずに済むので、非常に便利です。
OCRソフトを使用する時、まず画像の構造が分析され、ページがテキストブロック、表、画像などの複数のセクションに分割されます。単語と文字の分類が完了した後、一連の画像と比較し、多数の仮説を提案します。処理完了後、プログラムは最終的に認識可能なテキストを表示します。
- マトリックスマッチング — 画像をピクセル単位で格納されたグリフと比較します。
- 特徴検出 — グリフが線分、閉じたループ、線の方向、線の交差などの “フィーチャ (特徴)” に分解されます。検出機能は、表現の次元性を低下させ、認識プロセスを計算上効率的にします。これらのフィーチャは、文字の抽象的なベクトルのような表現と比較され、1つ以上のグリフプロトタイプに縮小されます。コンピュータビジョンにおける特徴検出の一般的なテクニックは、一般的にインテリジェント手書き文字認識と実際に最も近代的なOCRソフトウェアで使われます。
膨大な書類の中から必要な情報を探す場合、文書検索ができ大きな効率化につながるでしょう。コピペや編集も簡単に行えるため、紙資料で保管するよりも管理にかかる手間が大幅に減ります。共有が簡単になり安全性も高まります。OCR機能の活用で、仕事の効率が大幅に向上できます。
日本語/英語/フランス語/ドイツ語/ロシア語/イタリア語/ポルトガル語など多言語変換に対応。OCRモードで言語を選択して、文字認識の成功率を高めることができます。
対応OS:Windows 10/8.1/8/7/Vista/XP(32bit/64bit)
- 複数言語を対応し、操作は簡単。
- スキャンPDFと画像から文字認識可能。
- 一括処理対応。
- OCR精度が高い。
- PDF編集機能もあります。
デメリット:
- Windowsのみ対応します。

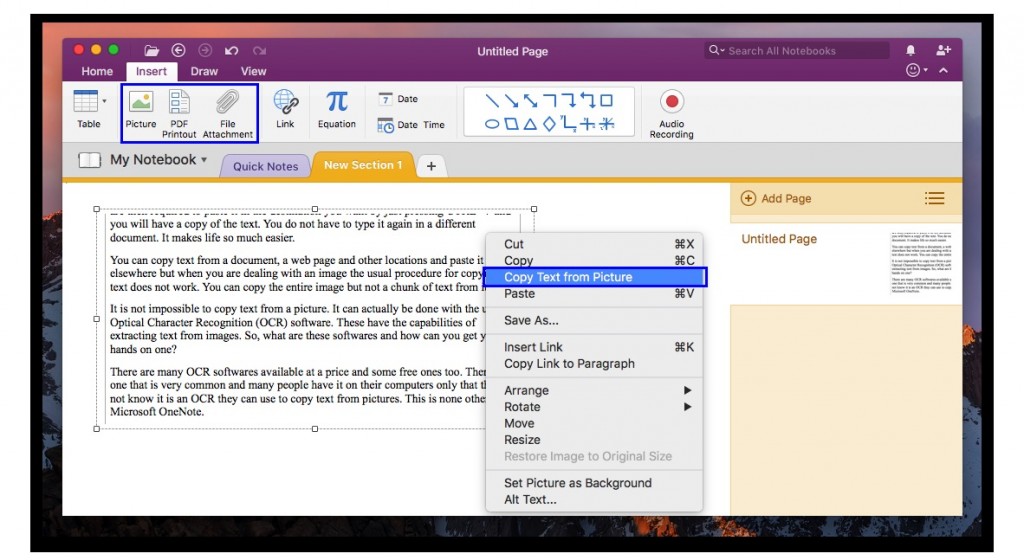
OneNoteに画像を挿入し、画像を右クリックして、[テキストをコピー]をクリックすると、テキストをクリップボードに保存しコピーできます。印刷ファイルからテキストを抽出する場合も、操作は同じです。ページを右クリックして、[この印刷ページからテキストをコピー]をクリックします。
- 単純なテキスト画像を処理する場合、精度は90%以上に達します。
- スキャンPDFと画像の認識も対応。
- 使いやすい。
- フリーソフト。
デメリット:
- フォームなどを含む複雑なファイルを認識するとき、精度が低い。
- 一括処理はできません。
- クラッシュすることがあります。
Microsoft OneNoteと同じ、OCR識別精度は画像の品質によって異なります。
対応OS:Windows 10 / 7 /8 /XP /Vista
- スペルチェッカーが組み込まれます。
- 一括処理もできます。
- フリーソフト。
デメリット:
- 直接コピーできず、先にWordまたはテキストに出力する必要があります。
- 機能が少ない。
- 3つの言語のみ対応します。
- フォントとフォーマットの検出はありません。
- 画像(TIFF,JPG,BMP)のみ対応し、PDFを対応しません。
Boxoft Free OCRでテキストを編集できます。Microsoft Officeがなくても、OCRで認識されるテキストを編集できます。また、PDFページの修正、トリミング、回転などの最適化機能も提供します。
対応OS:Windows 2000/2003 / XP / Vista / 7 / 8 / 10
- 指定ページを変換可能。
- 操作は簡単。
- 複数の言語を対応します。
- OCR抽出した文字を編集可能。
デメリット:
- Windowsのみ対応。
- 更新はしていません。
- 手書きの文字を認識できません。
- PDF対応しません。
対応OS:Windows 2000/2003 / XP / Vista / 7 / 8 / 10
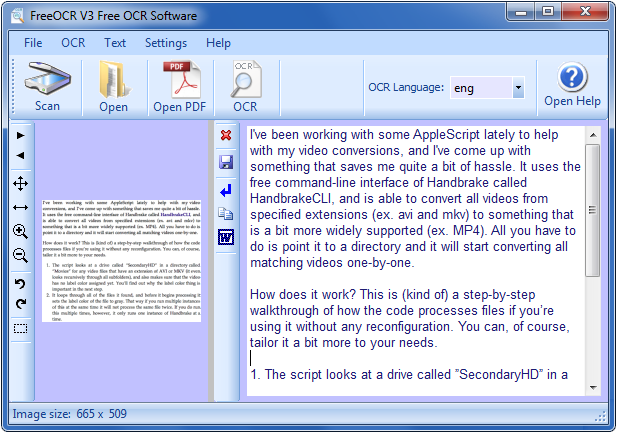
- フリーソフト。
- 任意のスキャナーを対応します。
- 画像を拡大できます。
- Tesseract OCRエンジンの精度は高い。
デメリット:
- PDFの最初のページのみ認識できます。
- 1時間あたり10枚の写真/ファイルのみアップロードできます。
- プレーンテキストのみ出力できます。
- テキスト形式は保持できません。
ソフトは100以上の言語を認識でき、20の言語での翻訳をサポートします。最新バージョン(1.4.2以降)は、20回のみ無料利用できます。ただし、古いバージョンは引き続き無料で使用できます。
対応OS:Windows 10/8.1/8/7/Vista/XP、Mac
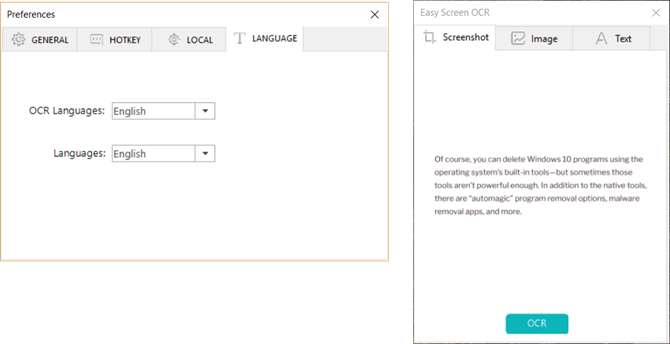
- 使いやすい。
- 2つのOCRモードあり、100以上の言語を識別できます。
- 識別した文字をほかの言語に翻訳できます。
デメリット:
- キャプチャしたもののみ識別できます。
- 認識した文字をほかの形式に変換できません。
対応OS:Linux、Windows
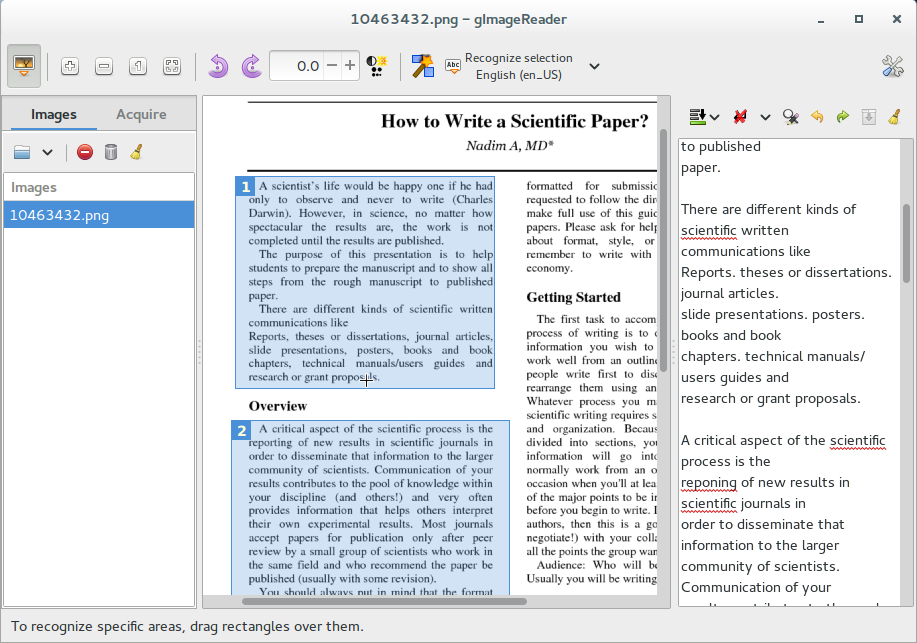
- Tesseract OCRエンジンは高い精度があります。
- 識別範囲を指定できます。
- JPEG,GIF,PNG,TIFF画像、PDFを対応します。
デメリット:
- TXTのみ出力できます。
- Macを対応しません。
- ほかの言語を識別する操作は複雑です。
対応OS:Windows、Mac
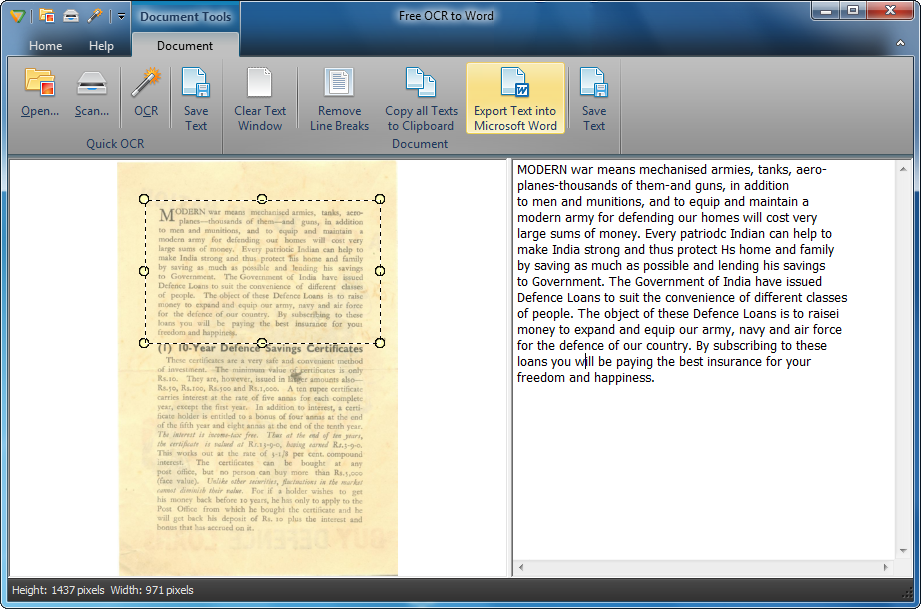
- 操作は簡単。
- ほとんどのスキャナーと接続できます。
デメリット:
- 文字フォントを識別できません。
- PDFおよび複数ページのファイルはサポートしません。。
- 英語のみ対応します。
対応OS:Windows、Mac
- 速度が速く、一括変換も対応。
- 複数の言語を識別できます。
- 複数のPDF編集機能があります。
デメリット:3ページのみ無料処理できます。
① Renee PDF Aideをダウンロードしてインストールし、ソフトウェアを実行して、Convert PDF部分を選択します。
② 上部の出力形式で「Word」を選択します。
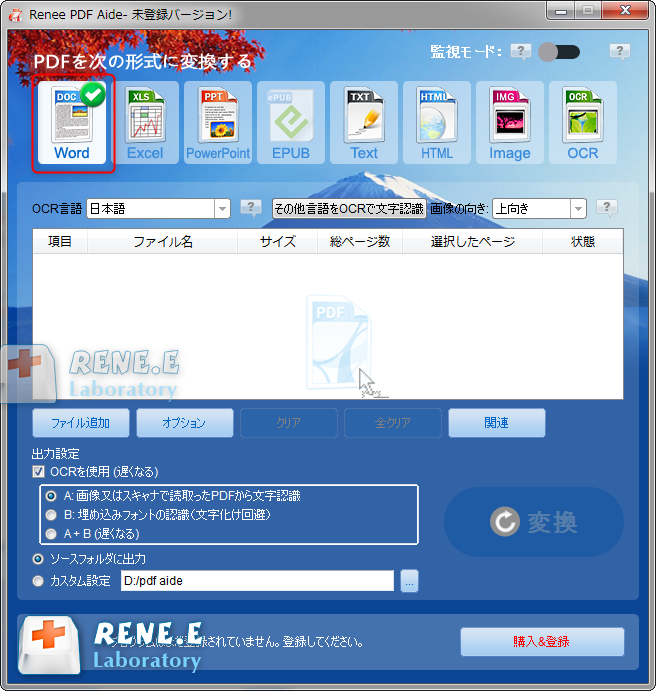
③「ファイル追加」ボタンをクリックし、変換するページを指定できます。「OCRを使用」にチェックを入れ、「変換」ボタンをクリックします。
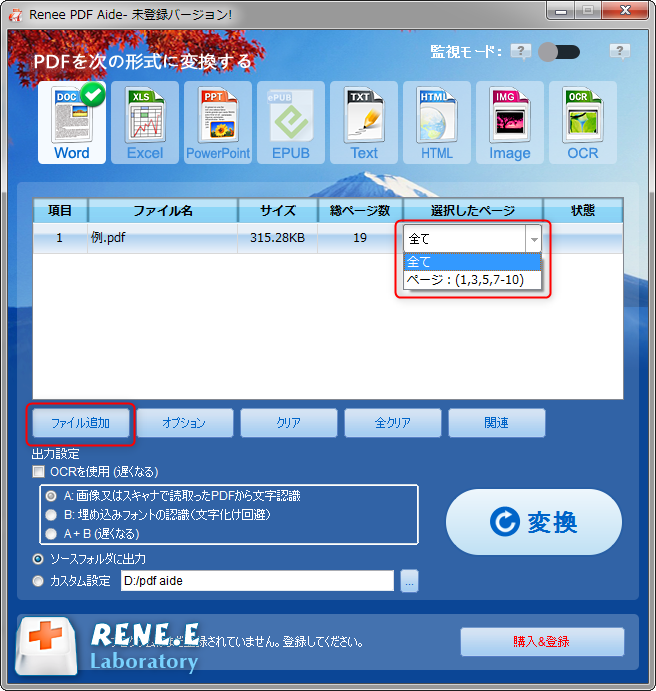
- A:画像又はスキャナで読み取ったPDFから文字認識:このオプションは、スキャンされたPDFファイルまたは画像の変換に適しており、OC技術を利用して、テキスト認識の精度をさらに向上させることができます。
- B:埋め込みフォントの認識(文字化け回避):このオプションは、フォーマット変換の完了後にファイル内の文字化けを回避するために、PDFソースファイルに埋め込みフォントがある状況に適用できます。
- A+B(遅くなる):プログラムは、ファイル内のフォントが画像であるかPDF埋め込みフォントであるかを自動的に認識し、変換して出力します。 ただし、認識には時間がかかり、変換時間は長くなります。
① Renee PDF Aideをダウンロードしてインストールし、ソフトウェアを実行して、Convert PDF部分を選択します。
② 上部のメニューバーでOCRを選択し、[ファイル追加]ボタンをクリックし、PDFファイルをインポートします。
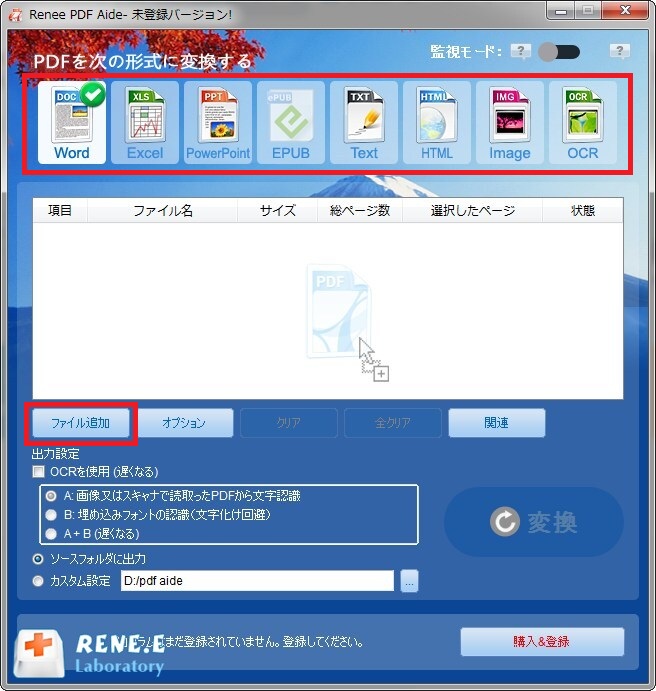
③ [OCR言語]で対応する言語を選択します。[その他言語をOCRで文字認識]ボタンをクリックして他の言語パックをダウンロードすることもできます。対応する言語パックを選択した後、[画像の向き]オプションで画像に対応する画像の方向を選択します。OCRが画像テキストをスムーズに認識できるようにするためです。
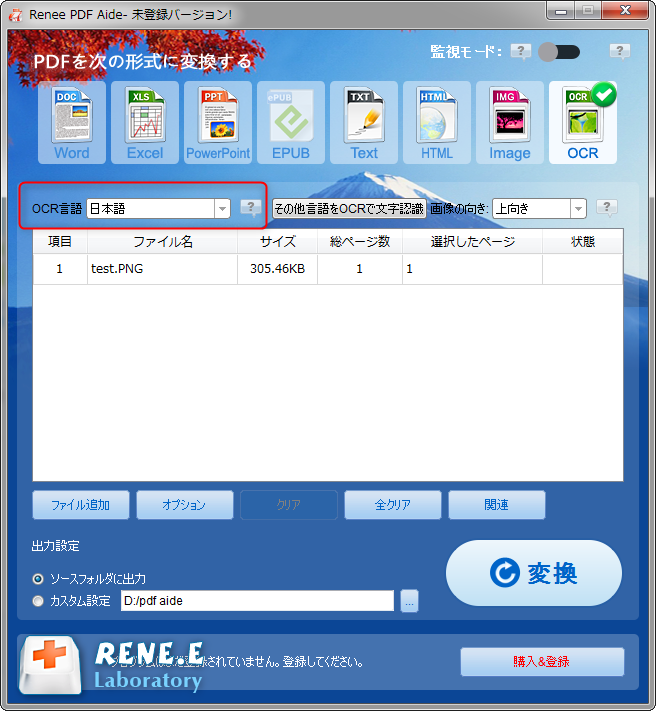
④ 出力場所を設定し、「開始」ボタンをクリックします。
以上は9つのOCRソフトを紹介しました。多機能やOCRの高精度の特徴があるRenee PDF Aideは一番おすすめです。PDF変換やPDF編集等の機能があります。
関連記事 :

2022-06-14
Ayu : スキャンされたPDFを編集可能な形式に変換したい場合、OCR機能を利用する必要があります。この記事は、フリーのOCRソフト、オン...

2022-06-14
Yuki : PDF文書に文字を書き込みたい、注釈を追加したい時、どうしたらいいでしょうか?この記事は簡単にできる4つの方法を紹介します。あわ...

2022-06-14
Satoshi : PDFファイルサイズが大きい場合、転送や共有などの時は不便です。この記事は、PDFを圧縮するソフトやオンラインPDF圧縮ツールと...
2022-06-14
Imori : PDFに必要のないページを分割して削除したい場合、プロのPDF編集ソフトが必要です。この記事は、プロなPDF編集ソフトをすすめ、...
何かご不明な点がございますか?



